The bottleneck to your next wave of AI isn’t the model. It’s the data access layer.
AI works. You’ve proven it. The pilots landed, the use cases are real, and now the conversation has shifted from “should we do this” to “how do we do more of it.”
Here’s where it gets interesting, and genuinely harder: “more of it” requires more complex data access. More sources at the same time, tighter controls needed.
Enterprises are hitting this wall as we speak.
The first wave of enterprise AI was low-stakes and low-friction data access. Documentation assistants. Support agents that could only see your knowledge base. Internal tools running against sanitized exports. This wasn’t chance, smart teams chose these use-cases specifically because the scope could be small, and the data access simple: one API, broad permission.
The next wave requires AI Agents to access data the business actually runs on. Customer records in Snowflake. Transaction history in Postgres. HR data that lives across Workday and a legacy system nobody has touched in a decade. The data that’s regulated / sensitive, and spread across sources that were never designed to talk to each other.
And Enterprises are figuring out what this access looks like as we speak.
The answer so far hasn’t been pretty: months of work to aggregate the data, and ensure the controls table-stakes for a large enterprise.
Two stories. Two versions of the same wall.
A fintech company deployed a customer support agent, gave it API access to documentation, and proved good ROI. Now they wanted to expand — give the AI vendor access to customer data. To feel comfortable giving this data access, they needed:
- Aggregate data across multiple data sources
- Scoped to what the use-case requires
- Provision access just-in-time, and de-provision automatically
Nothing off the shelf solves this. OAuth to each source separately kind of solves #3, but leaves you with a bunch of service accounts to manage. #1 and #2 are the hard part, and usually requires engineers building custom stuff.
A major telco built an internal HR AI agent that needed data aggregated across Workday and an internal legacy database.
A full team spend a couple months building the curated dataset, to:
- Pull data from the Workday API
- Pull some curated fields from the legacy proprietary DB
- Ensure the compliance controls as well as performance on this new “API”
The telco knows there’s huge potential to automate operations across departments, and the curated access is the bottle-neck. In most cases teams know what data from where, but it’s a matter of building these curated aggregated views, with the controls they need.
Both of these stories show the ceiling in what current infrastructure can do.
Access patterns today were built for humans. AI doesn’t work that way.
The difficulty is specific, and it helps to name it clearly.
For some single data sources, you can get reasonably far. OAuth plus API access to Workday or ServiceNow is a workable approximation of controlled access. The limitation of OAuth plus API access is granularity: most vendor APIs weren’t built for precise data scoping. You can control which endpoints are accessible, but you can’t say “only these columns, only rows where region equals X, only for the next two hours.” Snowflake gets you closer with its native row and column controls — but you’re still scoping within one system, still creating standing configurations that need maintenance every time requirements change.
For multiple sources — which is almost every meaningful AI use case — the tooling largely falls apart. Your options are:
- Build bespoke APIs or views for each source and each use case
- Create standing “curated” datasets across sources and provision service accounts to them (standing, broad permissions)
- Accept broader access than you’d like.
The telco’s team lived through what the first option costs.
The other two carry their own weight: standing permissions that accumulate as a compliance liability, granularity compromises because you’re trying to serve multiple consumers with fewer datasets, and a maintenance burden that compounds every time a vendor needs one more field or an agent expands its scope.
The reason the gap exists is fundamental. Current access models — APIs, OAuth, service accounts, RBAC — was designed for humans making predictable, bounded requests. AI operates at machine speed, pulling from multiple systems simultaneously, with queries that shift and expand as the task evolves.
The infrastructure was never built for this. It’s not failing. It’s just not what it was designed for.
We are building that infrastructure.
IAM gets you to the door. It has no idea what happens inside.
Before getting to what we built, it’s worth addressing the instinct to reach for IAM tooling, because it comes up in every one of these conversations.
Identity providers answer the question of who is allowed in. That’s necessary, and we integrate with your existing IAM rather than replace it.
But a perfectly configured identity layer cannot scope or aggregate the data. It can tell you that an AI agent is authorized to access Snowflake. It cannot tell you that the agent should only see rows for customers in one region, with PII columns masked, joined with a field from Postgres, for the next thirty minutes, and then automatically lose that access when the task is done.
That level of control — row-level, column-level, time-bound, cross-source — is simply not what identity infrastructure was built to provide.
The gap between “authorized to access the system” and “accessing exactly the right slice of the right systems for exactly the right duration” is where the real problem lives.
IAM handles who gets through the door. It has nothing to say about what’s on the table once they’re in the room.
AlienGiraffe is provisioning the data. Not the permission.
Distributed systems and container technologies have matured dramatically in the last few years.
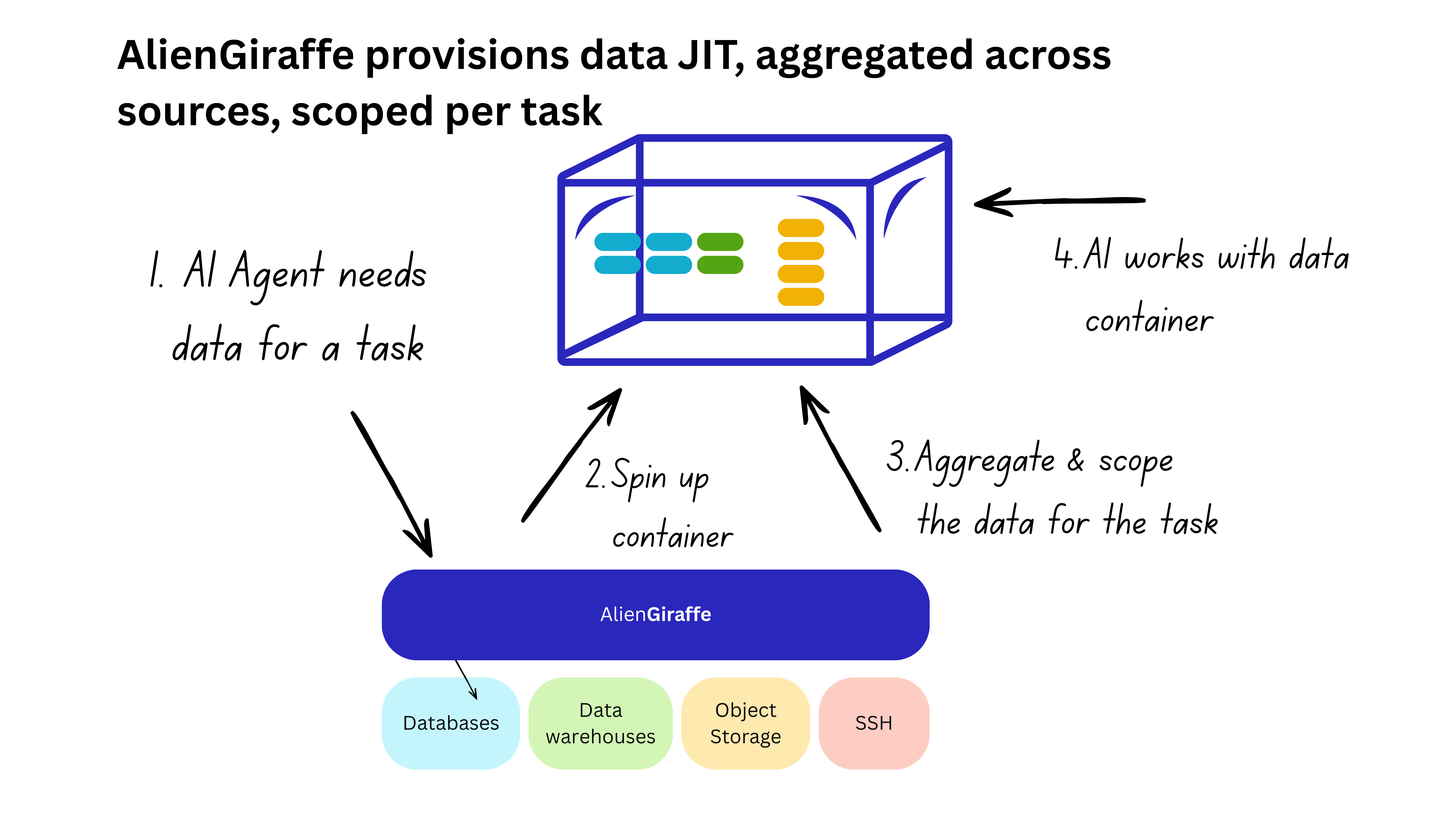
That matters here, because it means you can now do something that wasn’t practical before: provision the data itself, per task, on demand, rather than managing access to underlying systems or building standing aggregated datasets.
When an AI agent or vendor makes a data request, we don’t modify their access to existing systems — we spin up an ephemeral, isolated container loaded with exactly the slice of data that task requires. Postgres, Snowflake, S3, a legacy SSH system, wherever the data lives — pulled, joined, masked, and scoped per task, assembled in under a second.
The agent works with the container. The container tears down when the task is done. No standing credentials. Nothing persists.
This is the architecture that finally makes the telco story fast. The curated view across Workday and the legacy database — specific fields from each source, joined on demand — isn’t months of work. It’s a policy, defined once, provisioned automatically every time the agent needs it. The agent gets exactly the data it needs. Nothing more.
And when requirements change and it needs one more field, that’s a request and an approval, not a new build.
The precision this enables goes further than a policy layer on top of broad credentials ever could. Not just which tables are accessible — which rows, which columns, which joins, assembled from which sources, for which duration. All of it, provisioned on demand, in under a second, torn down automatically when the work is done.
Control built from the data layer makes you faster, not slower.
AI that can reach the data it needs without months of pipeline work, with access controls precise enough that the risk conversation stops being the bottleneck.
The other thing that changes with this architecture is how incremental access works — and this is where it starts to feel qualitatively different from anything the current model can do.
When an AI vendor needs one more column than their current scope allows, they request it. If it fits within the approved policy, it’s available immediately. If it requires an expansion, it triggers an approval — once. That approval is logged with the business justification, and from that point forward the vendor can request that field without going through the process again. No new service account. No new API build. No round-trip through a backlog.
For AI agents the implications are bigger still. An agent that discovers mid-task that it needs data it wasn’t provisioned for can request it incrementally. The request is logged with the intent. The justification is calibrated to the sensitivity of the data. You see exactly how the agent’s requirements evolved, you can approve or constrain in real time, and you have a complete audit trail from the original intent through every query and every escalation — not reconstructed after the fact, but recorded as a natural byproduct of how the system works.

That’s what turns the fintech story into a solved problem. The vendor gets access to Snowflake and Postgres, scoped precisely, time-boxed, every access event logged. Next use-case, they need a new field — one approval, and it’s available. The fintech’s team isn’t rebuilding infrastructure. They’re managing a policy. And every new AI use case that would have spent months waiting on an access build becomes something a team can unblock in days.
That’s the actual prize. Not compliance posture as an end in itself — though the audit trail will matter more as regulators get more specific about what data AI systems touched and why.
You can patch the old model. Or you can leapfrog it.
There’s a reason this is possible now and wasn’t three years ago.
Container orchestration, ephemeral compute, distributed systems at this speed and scale — the underlying technology has reached the point where you can load two gigabytes of tabular data into an isolated environment in under a second, serve sub-millisecond queries against it, and tear it down automatically when the task is complete. That performance profile changes what’s architecturally feasible.
The old model — standing credentials, bespoke views, service accounts that accumulate and need maintenance, access patterns designed for humans — was the right answer given the constraints that existed. Those constraints have changed.
The enterprises that recognize this now aren’t just managing risk more carefully. They’re building on a foundation that lets them move faster, deploy more ambitiously, and hand AI access to the data that actually matters — with the precision and auditability that production demands.
Alien Giraffe provisions just-in-time, task-scoped data access for AI agents and vendors — aggregated across your data estate, fully deployed in your environment.